If you even wondered what is the palette AWS is using in the official diagrams and presentations, below you will find my first attempt of publishing an unofficial color pallete. Unfortunatelly I could not find an official one, if you ever find one please do let me know.
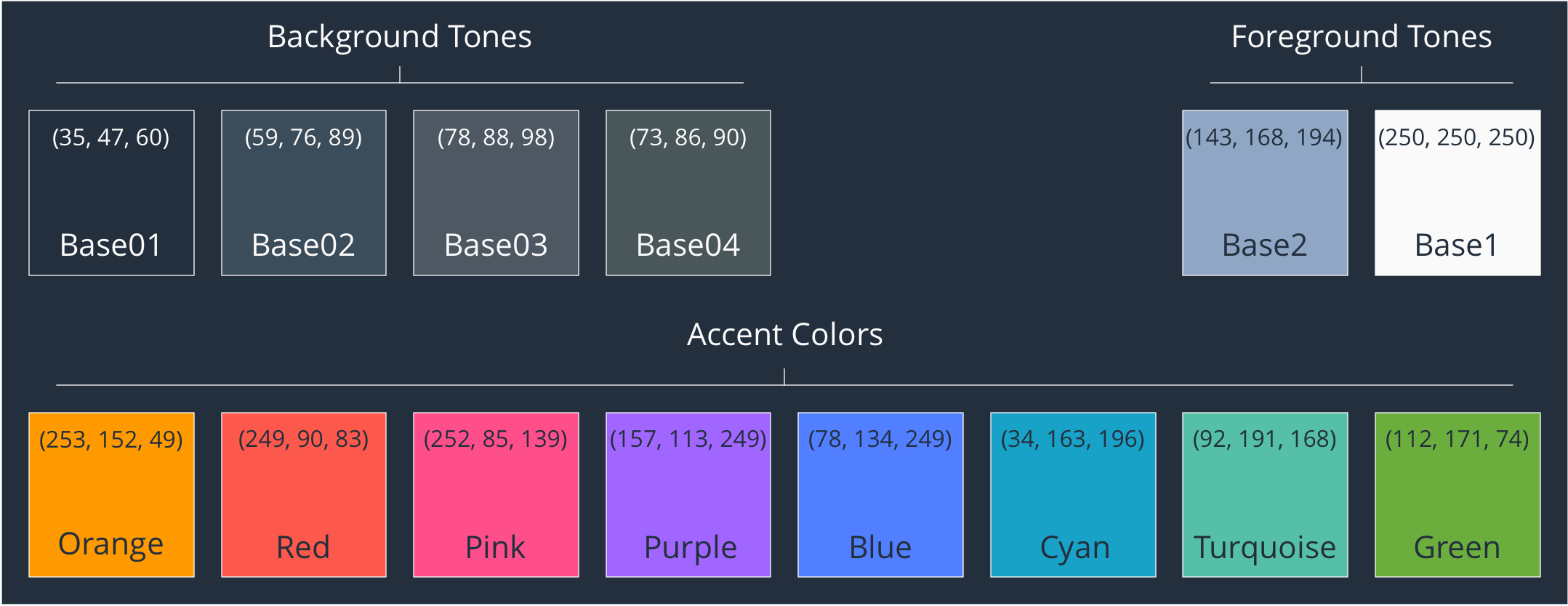
Both the dark and the light palettes are using 4 Background Tones with 2 Foreground Tones each, complemented by 8 Accent Colors. Pretty simple but with a consistent and fascinating effect.
First things first, the dark background palette:
And probably the most used one, the light background palette:

I added the RGB values as well if you ever want to recreate it in OmniGraffle or Visio for you own needs. This is Generic RGB.
I do not yet know the reasons why these specific colors where chosen; I do have the feeling they started with Red 700 as a base Monotone color and worked from there, but this is just a feeling for now.
PS: Please do not ask for an Azure one because I already looked into it and everything is just a mesmerising rainbow there for now.